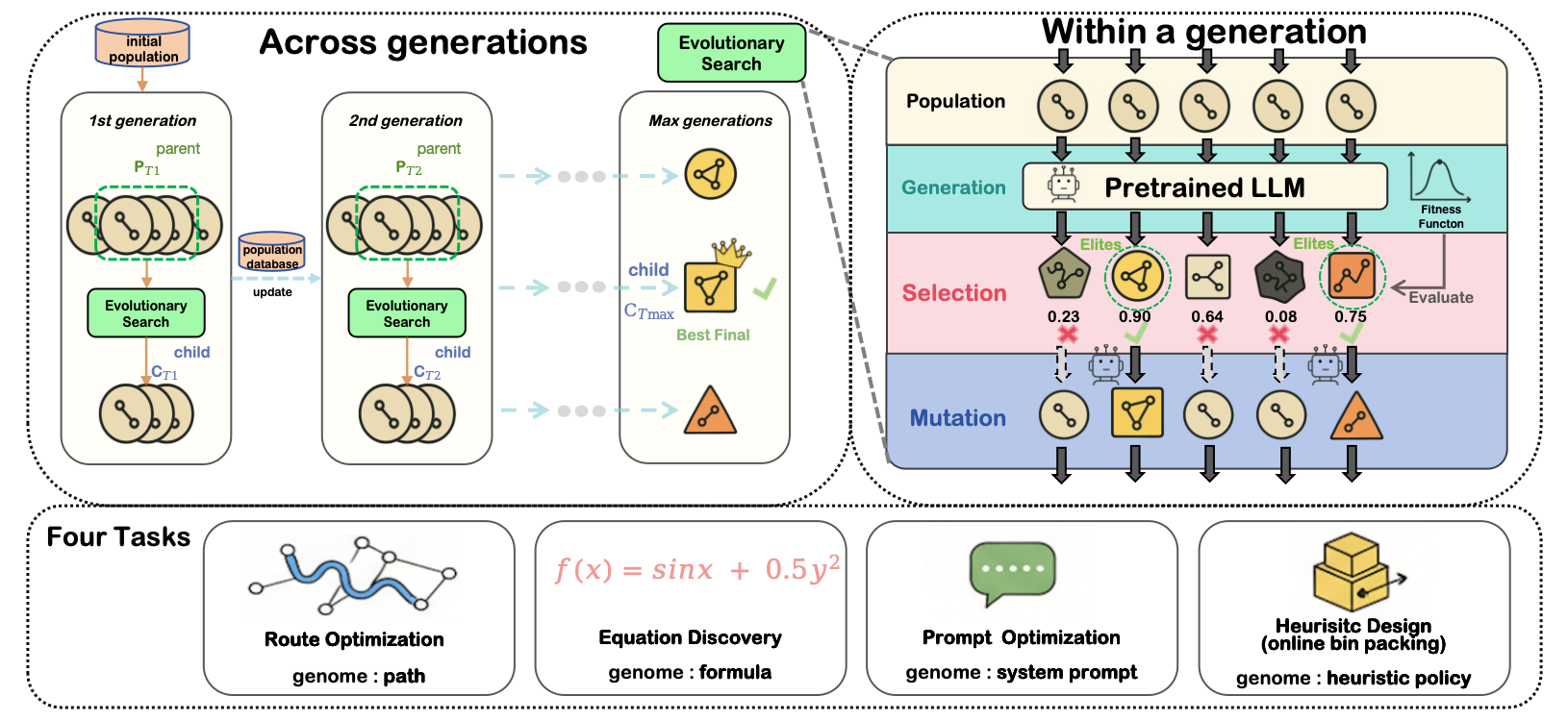
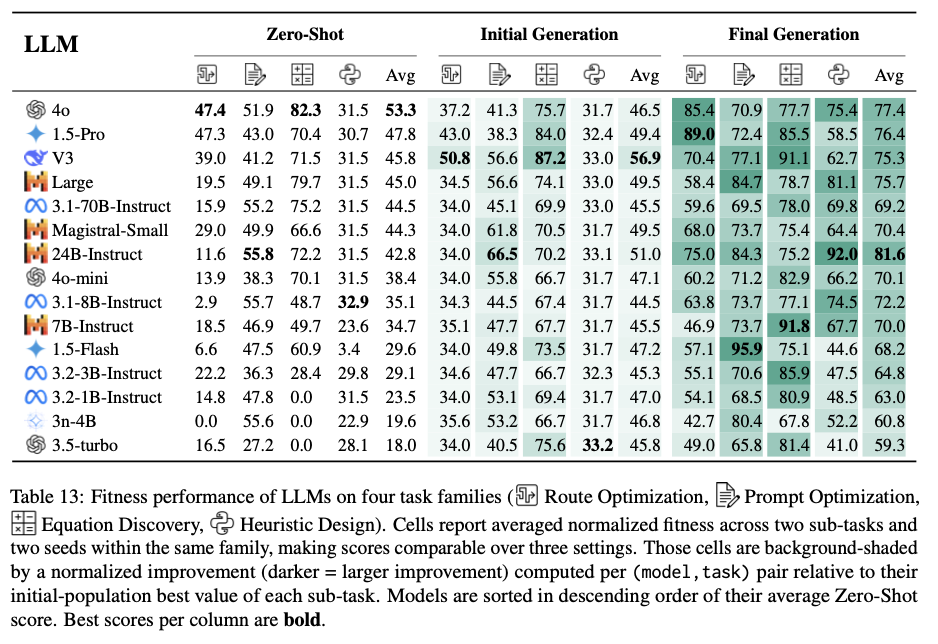
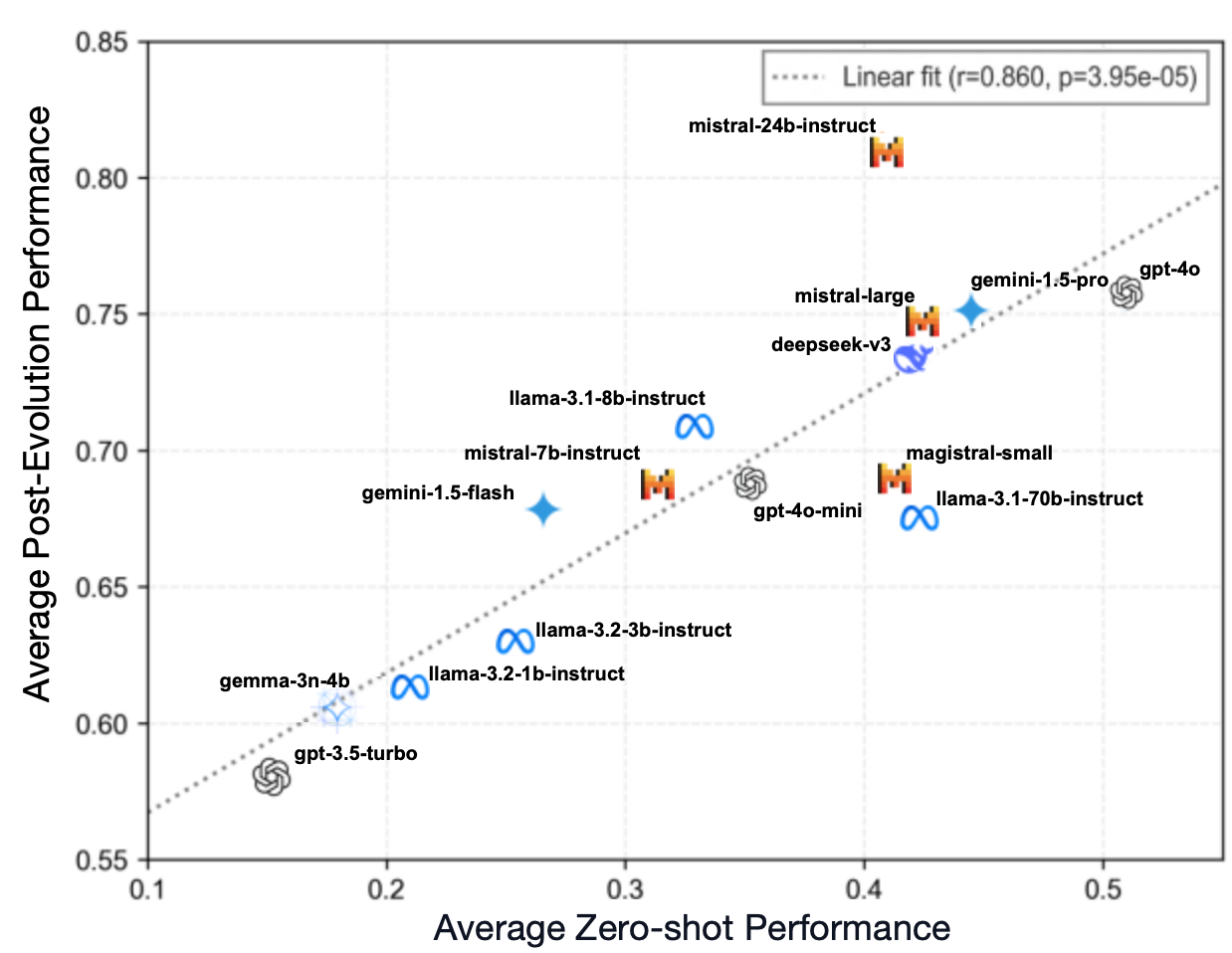
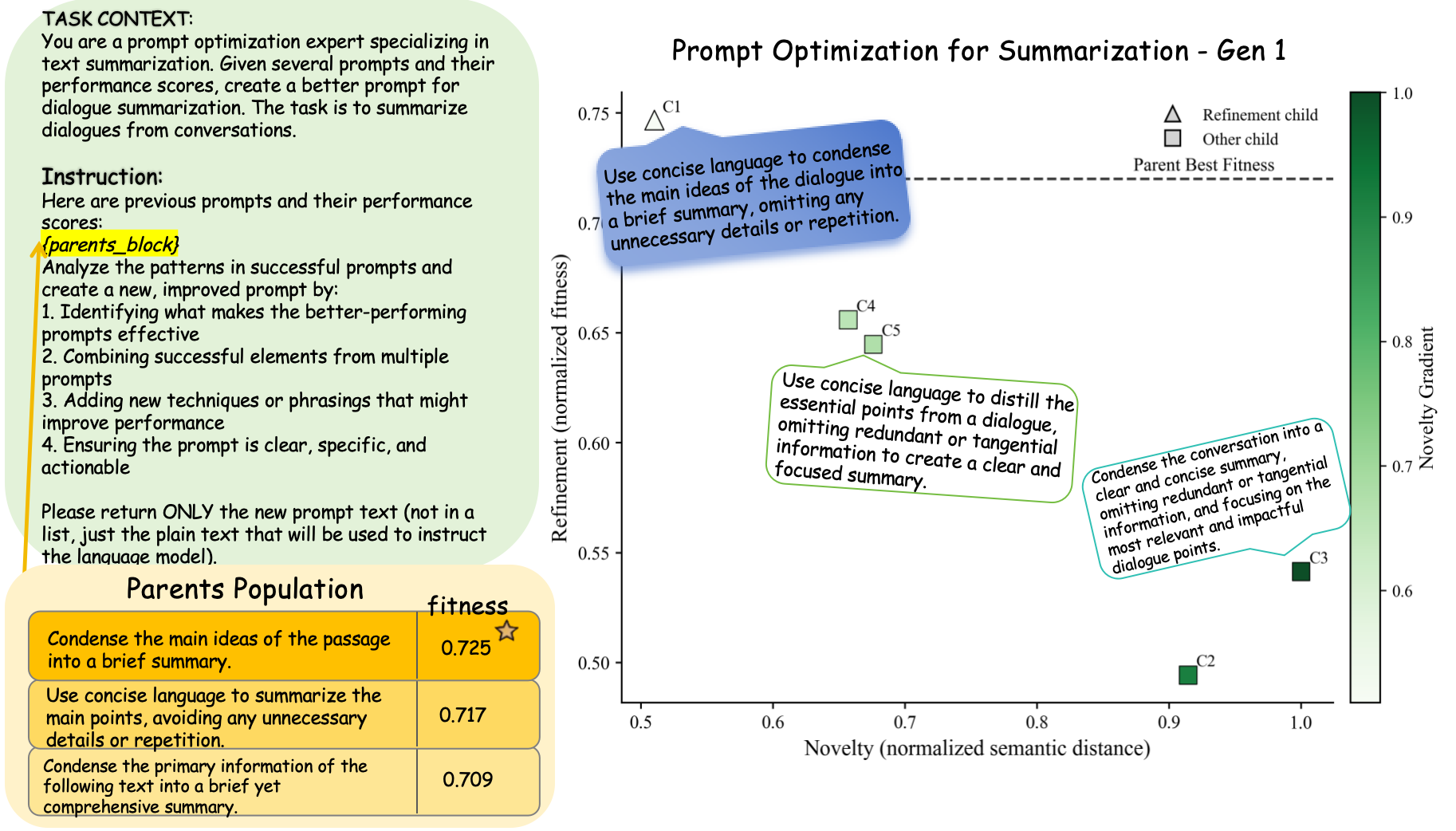
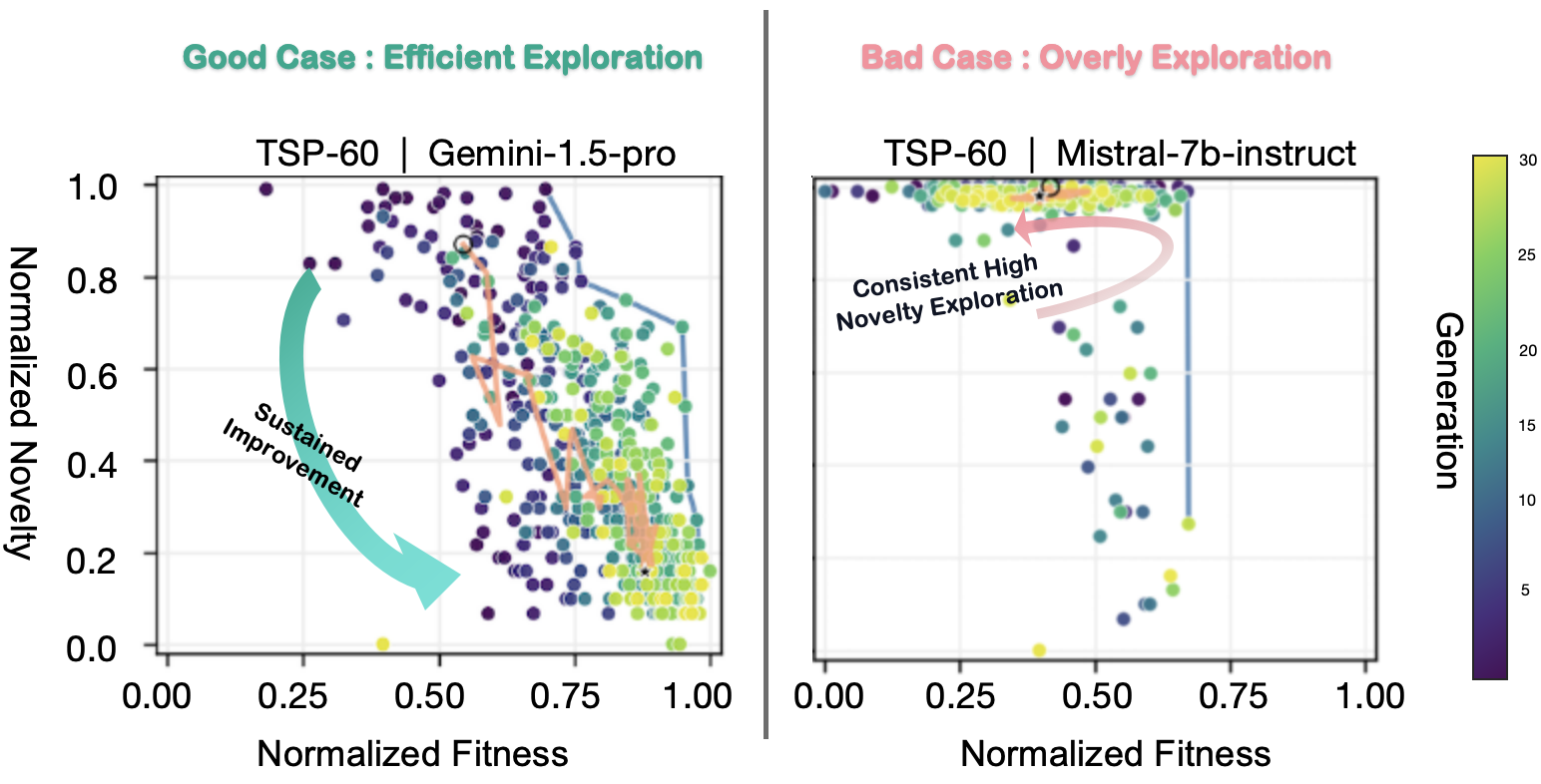
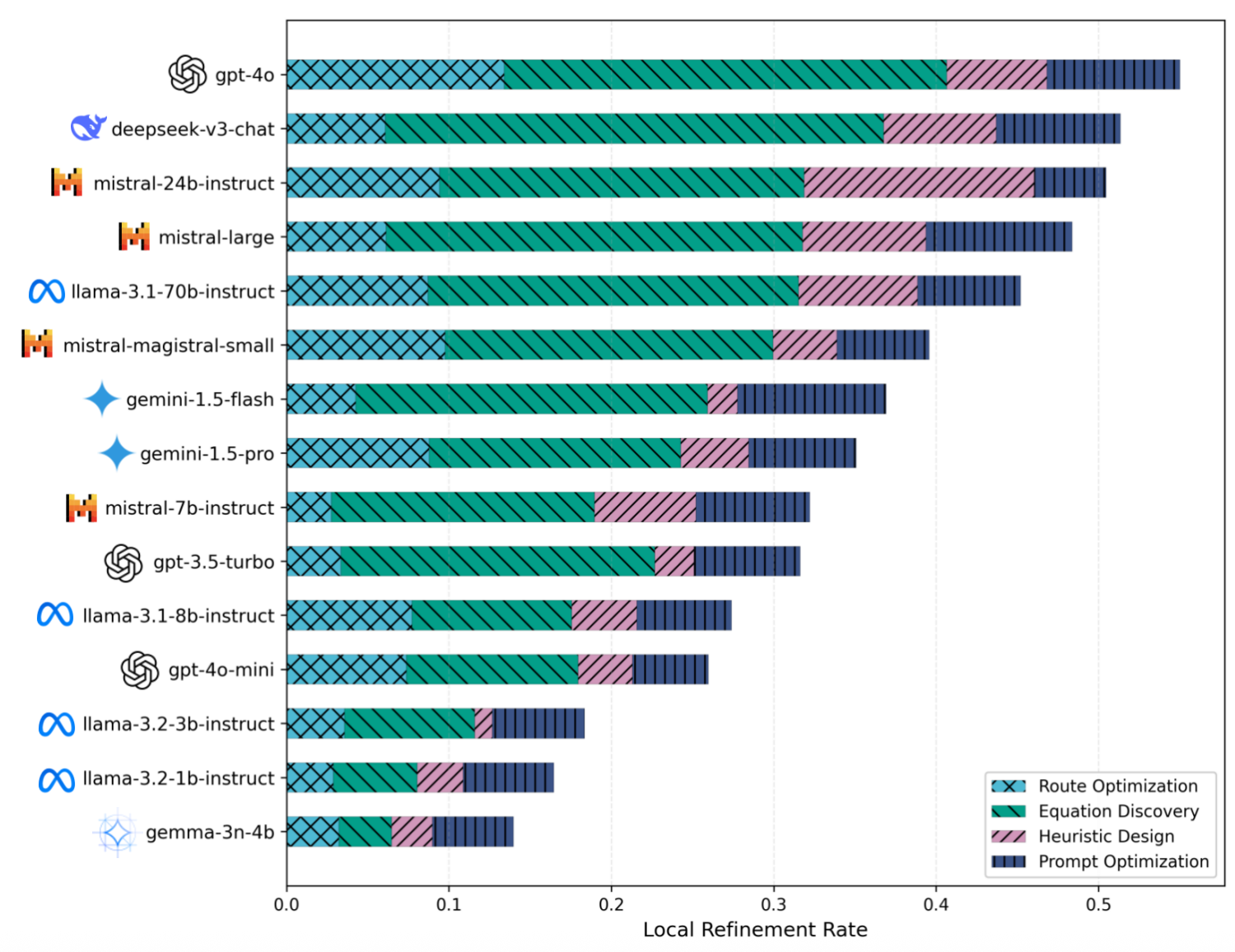
Recent work has demonstrated the promise of orchestrating large language models (LLMs) within evolutionary and agentic optimization systems. However, the mechanisms driving these optimization gains remain poorly understood. In this work, we present a large-scale study of LLM-guided evolutionary optimization, collecting optimization trajectories for 15 LLMs across 8 optimization problems. While base problem-solving ability, measured via zero-shot performance, correlates with final optimization outcomes, it explains only part of the variance: models with similar zero-shot capability often induce dramatically different search trajectories and final performance. To explain this gap, we analyze breakthrough dynamics and the geometry of optimization trajectories in the semantic space of candidate solutions. We find that effective LLM optimizers behave as strong local refiners, progressively localizing their search while producing frequent, incremental improvements across generations. In contrast, weaker optimizers exhibit large semantic drift, with occasional large breakthroughs followed by prolonged stagnation, reminiscent of behavior observed in classical metaheuristics. Notably, various measures of solution novelty do not predict final performance; novelty is beneficial only when the search remains sufficiently localized around high-performing regions of the solution space. Our results highlight the importance of trajectory-level evaluation for understanding and improving LLM-based agentic optimization systems, and provide actionable insights for future work on learning to search.
Curious to see how different LLMs navigate the solution space?
Go straight to explore the trajectories interactively